The DNA of Modern AI: Text Encoding and Vector Databases Explained
Every AI application starts with a translation problem.
Every AI application starts with a translation problem.
Humans speak in words. Machines calculate in numbers. The gap between these two languages is where text encoding lives: the foundational process that converts your messy, ambiguous human language into the clean mathematical structures that LLMs can actually process.
But encoding is only half the story. The other half is storage. Vector databases give LLMs the long-term memory they need to scale beyond a single conversation. Together, these two systems form the infrastructure layer that makes modern AI applications possible.
Here’s how they work, why they matter, and what enterprises need to control.
Tokenization: Breaking Language Into Pieces
Text encoding starts with tokenization. Before an LLM can understand anything, it needs to break your input into digestible units called tokens.
Tokens aren’t always full words. They’re fragments: pieces of language that the model has learned to recognize during training. The word “unhappy” might get split into “un” and “happy.” The phrase “AI governance” could become three tokens: “AI,” “gov,” and “ernance.”
Modern tokenizers like Byte Pair Encoding (BPE) and WordPiece optimize for efficiency. They identify the most frequently occurring character sequences in training data and encode them as single tokens. Rare words get broken down into smaller chunks the model has seen before. Common words get represented as single tokens.
Why does this matter? Token count directly impacts cost and latency. Every token you send to an LLM API costs money. Every token the model processes adds milliseconds to your response time. GPT-4 processes roughly 4 characters per token in English. A 1,000-word document might consume 1,300 tokens.

Tokenization is deterministic. The same input always produces the same tokens. But the encoding that happens next is where things get interesting.
Encoding: From Tokens to Vectors
Once text is tokenized, the model needs to encode those tokens as numbers. This is where word embeddings come in.
An embedding is a dense vector: a list of floating-point numbers: that represents the meaning of a token. The magic is that similar words produce similar vectors. The embedding for “happy” sits closer to “joyful” than to “database” in vector space.
This isn’t random. Embeddings are learned during training through backpropagation. The model adjusts these vectors to minimize prediction errors across billions of text examples. Over time, the vectors arrange themselves geometrically so that semantic relationships become spatial relationships.
The vector for “king” minus the vector for “man” plus the vector for “woman” gets you close to “queen.” That’s not a trick: that’s geometry capturing linguistic patterns.
Modern transformer models like GPT and BERT create contextualized embeddings. The same word gets different vectors depending on its surrounding context. “Bank” in “river bank” encodes differently than “bank” in “savings bank.” The attention mechanism in transformers enables this context-awareness by allowing each token to reference every other token in the input sequence.
The Vector Space: Where Meaning Lives
Think of vector space as a multidimensional map where every possible concept has coordinates.
Embedding models typically output vectors with 768, 1024, or 1536 dimensions. Humans can’t visualize 1,536-dimensional space, but the math doesn’t care. Each dimension captures some aspect of meaning: syntax, semantics, sentiment, domain specificity. The exact meaning of each dimension is opaque even to the model’s creators, but the geometric relationships between vectors remain consistent.
Distance matters. Cosine similarity measures how close two vectors are in this space. A similarity score near 1.0 means the concepts are nearly identical. A score near 0 means they’re unrelated. This metric powers semantic search: finding documents that mean the same thing even if they use different words.

Vector space is where LLMs do their reasoning. Every operation inside a transformer model is a transformation in this space. Attention weights determine which vectors influence which other vectors. Feed-forward layers project vectors through learned transformations. The entire inference process is geometry: billions of matrix multiplications that navigate this conceptual landscape.
Vector Databases: The Memory Layer
LLMs have a context window problem. GPT-4 can handle roughly 128,000 tokens of context: about 300 pages of text. Beyond that limit, the model forgets. It can’t reference information that happened earlier in the conversation or exist in your enterprise knowledge base.
Vector databases solve this. They store embeddings with metadata and enable fast similarity search across millions or billions of vectors.
The architecture is purpose-built for retrieval. Traditional databases index rows and columns. Vector databases index high-dimensional coordinates. They use algorithms like HNSW (Hierarchical Navigable Small World) or IVF (Inverted File Index) to approximate nearest-neighbor search without comparing every vector in the database.
Popular vector databases include Pinecone, Weaviate, Qdrant, and Chroma. Each offers different trade-offs between speed, accuracy, scale, and cost.
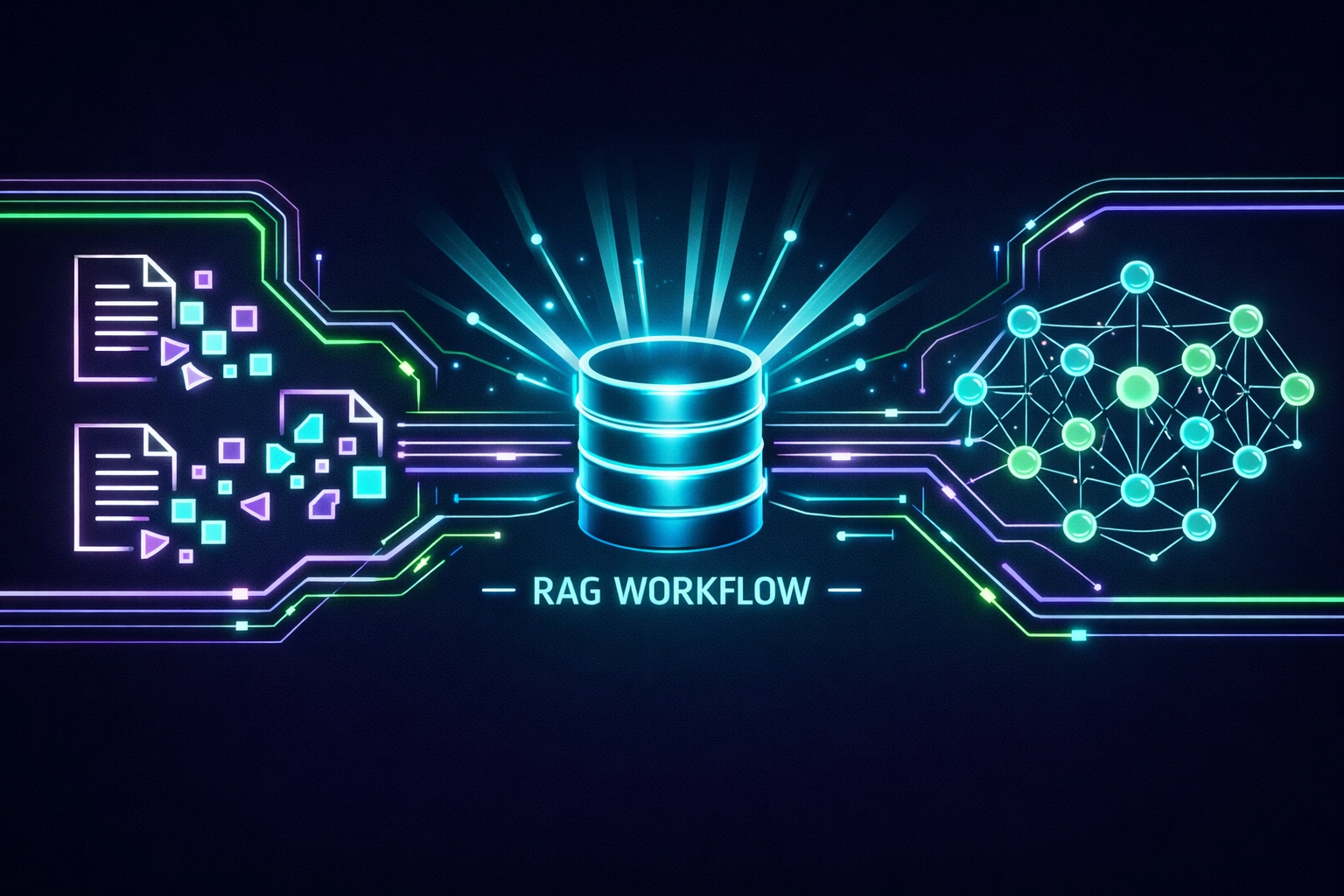
Here’s the standard workflow:
- Chunk your documents into passages (typically 200-1000 tokens each)
- Generate embeddings for each chunk using an embedding model
- Store the embeddings in the vector database alongside the original text and metadata
- At query time, embed the user’s question
- Retrieve the top-k most similar chunks
- Inject those chunks into the LLM’s context window as additional information
This is Retrieval-Augmented Generation (RAG). The LLM doesn’t need to memorize your entire knowledge base during training. It retrieves relevant information dynamically at inference time.
How LLMs Use Both Together
Text encoding and vector databases create a closed loop.
When you send a prompt to an LLM, the model first encodes your input into vectors. Those vectors get processed through attention layers and transformed into output vectors. The output vectors get decoded back into tokens, which get converted back into text.
But with RAG, there’s an intermediate step. Before the LLM generates its response, your application embeds the user query, searches the vector database for relevant context, and injects that context into the prompt. The LLM now has access to information it was never trained on: your proprietary documents, recent data, customer records.
This architecture separates knowledge from reasoning. The vector database holds facts. The LLM applies logic. You can update your knowledge base without retraining the model. You can swap out embedding models or LLMs without rebuilding infrastructure.
It’s modular. It scales. It’s how production AI systems actually work.
The Enterprise Governance Problem
Here’s where control enters the picture.
Vector databases contain your most sensitive information encoded as numbers. Employee records, customer data, financial documents, proprietary research: all converted into embeddings and stored in third-party infrastructure. The vectors themselves might seem abstract, but they encode real information that can be decoded or inferred.
Who can search what? How do you implement access controls on vector similarity search? If an employee queries the vector database, can they retrieve chunks from documents they don’t have permission to read? Traditional RBAC (Role-Based Access Control) doesn’t map cleanly to vector space.
Metadata filtering helps. Most vector databases support filtering results by metadata fields before returning matches. You can tag chunks with access levels, departments, or sensitivity classifications. But this requires careful data architecture upfront. Miss a tag, and you’ve created a data leak vector.
Embedding models also introduce risk. They’re trained on public internet data that includes biases, stereotypes, and potentially problematic associations. Those biases get encoded into the vector space. Similar concepts cluster together: including concepts you don’t want associated in a professional context.
Observability matters. You need to track what gets embedded, where it’s stored, who queries it, and what results get returned. Without logging and monitoring at the vector layer, you’re running AI infrastructure blind.
Platforms like AXIOM Studio provide governance controls specifically designed for AI infrastructure. Instead of bolting compliance onto your vector database after deployment, you build it into the architecture: access policies, audit trails, data lineage tracking from source document to embedded chunk to retrieved context to LLM output.
The Bottom Line
Text encoding converts language into geometry. Vector databases store that geometry at scale. LLMs navigate that geometry to generate responses.
This isn’t abstract theory. It’s production infrastructure. Every enterprise AI application depends on these systems working correctly, securely, and under policy controls.
The companies that treat text encoding and vector databases as governed infrastructure assets will scale AI responsibly. The ones that treat them as black boxes will leak data, violate compliance requirements, and learn expensive lessons.
The DNA of modern AI is mathematical. But the consequences are very human.
Frequently Asked Questions
What is text encoding in AI? Text encoding is the process of converting human language into numerical representations (vectors) that AI models can process. It involves tokenization (breaking text into fragments) and embedding (mapping tokens to dense vectors in high-dimensional space where semantic relationships become spatial relationships).
How do vector databases differ from traditional databases? Traditional databases index rows and columns for exact lookups. Vector databases index high-dimensional coordinates and use algorithms like HNSW to perform fast approximate nearest-neighbor search across millions of vectors. This enables semantic search: finding content by meaning rather than exact keyword matches.
What is Retrieval-Augmented Generation (RAG)? RAG is an architecture that gives LLMs access to external knowledge at inference time. Your documents are chunked, embedded, and stored in a vector database. When a user queries the LLM, relevant chunks are retrieved via similarity search and injected into the context window, grounding the response in your actual data.
Why do vector databases create governance challenges for enterprises? Vector databases store your most sensitive information as embeddings: employee records, customer data, proprietary research. Traditional access controls don’t map cleanly to vector similarity search, creating potential data leak vectors. Enterprises need metadata filtering, access tagging, and observability at the vector layer to maintain security.
How does AXIOM help govern AI infrastructure like vector databases? AXIOM provides governance controls designed for AI infrastructure, including access policies, audit trails, and data lineage tracking from source document to embedded chunk to LLM output. Get started for free to build governance into your AI architecture from day one.
Written by
AXIOM Team