The Agentic Economy: Where Are We Heading?
The agentic economy has a structure now — six layers from silicon substrate to Economics, with direct parallels to the pre-AI CPU/OS/K8s stack. A field map of where it goes next and how to ride out the tokenomics gap.

Three years ago, “AI” meant calling an API. Today it means operating a system: models that reason, protocols that wire them together, orchestrators that route work, governance layers that keep auditors happy, and a cost structure that nobody has quite figured out how to make sustainable.
That progression is not random. The agentic economy has settled into a six-layer stack — and each layer maps almost one-to-one onto a layer of the pre-AI CPU/OS/Kubernetes stack the industry has already learned to operate. Each layer carries its own technologies, its own unsolved problems, and its own bend point. Understanding where the next twelve months actually go means understanding what is pressing at each layer right now, how the layers compose into a system whose unit economics are honest enough to outlast the current wave of subsidies, and where the parallels to the older stack hold (and where they break).
This is a field map of that system. What it looks like, where it strains, and where the durable bets sit.
The agentic stack at six layers
| Layer | What it actually decides | Where it shows up today |
|---|---|---|
| Silicon (substrate) | The raw compute every higher layer is paying for | GPUs (NVIDIA H100/B200, AMD MI300), TPUs (Google v5), Trainium (AWS), MI (Apple, Cerebras) |
| LLM (runtime) | The model that interprets context and decides what comes next | GPT (OpenAI), Claude (Anthropic), Gemini (Google), Llama (Meta), DeepSeek, Mistral — with MoE (Mixtral, GPT-4o) and MLA (DeepSeek V3) as runtime architecture |
| Action | How intent becomes a side-effect in the world | ReAct pattern, MCP (Anthropic, 2024), A2A (Google, 2025), LLM Gateway and MCP Gateway (Portkey, Helicone, Axiom), RAG (LlamaIndex, pgvector, Vespa) |
| Governance | What is allowed, enforced at runtime not in a slide deck | Policy engines (OPA, Cedar), request-path enforcement (Portkey, Axiom) |
| Orchestration | How a hundred model calls become one coherent task | Coding agents (Claude Code, Cursor, Devin, Codex CLI), orchestrators (OpenClaw, LangGraph) |
| Economics | Whether the bill survives the end of the subsidy era | Per-task pricing (Devin at \$20/task), per-token (OpenAI, Anthropic), outcomes-based (emerging) |
Reading top-to-bottom is the engineer’s view: silicon provides the raw compute substrate, an LLM runtime turns that compute into context-conditioned reasoning, an action layer turns the model’s outputs into side-effects in the world, governance decides whether those side-effects are allowed, orchestration sequences the side-effects into coherent workflows, economics determines whether the whole thing is worth doing at scale.
Reading bottom-to-top is the operator’s view, and it is the more interesting read. If the economics do not work, none of the upper layers matter. If governance is missing, the orchestration is a liability. If orchestration is missing, the Action layer and the LLM runtime produce uncoordinated bursts of work that nobody can stitch into a deliverable. The bottom of the stack determines whether the top of the stack ever gets used in production — which is exactly why so many promising AI demos never quite become AI products.
The next sections walk each layer top-down, with the load-bearing pressures and the bets that look durable. But first, a parallel worth holding in your head: this is not the first stack the industry has built.
The pre-AI stack, for parallels
For comparison, here is the stack the industry built in the pre-AI era — the silicon-and-software stack every modern company already operates today:
| Layer | What it decided | Where it showed up |
|---|---|---|
| CPU (substrate) | The instructions that can execute at all | x86 (Intel, AMD), ARM (Apple Silicon, AWS Graviton), GPUs (used for graphics, not AI) |
| OS / runtime | What programs run and how they share resources | Linux, Windows, JVM, .NET, Node.js, Python runtime |
| Action | How programs reach the outside world | System calls, HTTP, gRPC, REST, SQL drivers, message queues |
| Governance | What a program is allowed to do | IAM, RBAC, firewalls / WAFs, OPA (originated here), Vault for secrets |
| Orchestration | How many components compose into one application | Kubernetes, Docker Compose, monoliths vs microservices, service meshes |
| Economics | Whether the cloud bill made sense | Per-VM (EC2, GCE), per-request (Lambda, API Gateway), reserved-instance discounts |
The parallels are not coincidence — they are the same architectural problems, solved with different primitives:
- CPU was the silicon then; GPU and TPU are the silicon now. Both are the raw compute every higher layer is paying for and trying to use more efficiently. The substrate row’s parallel is hardware-to-hardware — instructions on x86 become tensor ops on H100.
- Operating systems interpreted programs on CPUs; LLMs interpret context on GPUs. The OS row’s parallel is runtime-to-runtime — Linux turns binaries into running processes; an LLM turns a context window into a sequence of decisions. MoE is the LLM-runtime’s scheduling decision; MLA is its memory-management trick; both are the new “OS-level” question of how to run the workload cheaply on the silicon below.
- System calls and HTTP let programs act on the world; ReAct, MCP, A2A, and LLM/MCP gateways let agents act on the world. Different shape, same job. A protocol that decouples “what I want to do” from “how the call gets made” is the same engineering pattern showing up in a new domain. RAG sits here too — it is a tool call against a retrieval system, not an LLM-internal thing.
- IAM, RBAC, and WAFs governed what programs could do; OPA, Cedar, and request-path gateways now govern what agents can do. Notice that OPA appears in both tables — the same policy primitives transferred forward, because the governance question is the same.
- Kubernetes orchestrated services; OpenClaw and LangGraph orchestrate agents. A control plane that holds the state of many concurrent units of work is the same pattern in a different vocabulary.
- Per-VM and per-request pricing were how the cloud bill broke down; per-task and per-token pricing are how the AI bill is starting to. The economic layer is the youngest in both stacks, and the one most likely to determine which architectures survive.
The lesson the CPU-era stack teaches the agentic-era stack is the same lesson the agentic-era stack will eventually teach whatever comes next: each layer runs best on the substrate suited to its workload, and the architectures that win are the ones that respect that fit. A Kubernetes control plane does not run on a GPU. A vector similarity search does not run efficiently on a single x86 core. The sensible split is the one where each kind of work lands on the hardware its cost curve favors. The “sensible AI” thesis later in this post is, in the long view, just the next iteration of a lesson the industry has already learned once.
Layer 1 — Silicon substrate: GPUs and TPUs are the new CPU
The bottom of the agentic stack is silicon — GPUs (NVIDIA H100/B200, AMD MI300), TPUs (Google v5e/v5p), and the long tail of accelerators (AWS Trainium, Cerebras, Apple’s neural engine). This is the layer that does not need re-introducing; it is the layer everyone reads quarterly earnings about and the layer whose supply constraint defines the rest of the industry’s pace.
It is the substrate row’s parallel: where the CPU was the raw compute every Linux program eventually bottomed out into, the GPU/TPU is the raw compute every agent run eventually bottoms out into. Every prompt, every tool call’s prompt-wrapping, every RAG retrieval that gets stitched into context — they all bottom out in tensor ops on one of these accelerators.
Two operational facts shape the rest of the stack from here:
- The accelerator is the most expensive substrate, per useful operation, the industry has ever scaled. A token of inference is microseconds of GPU time, which is hundreds of microseconds of CPU-equivalent, which is many orders of magnitude more expensive than a CPU op. Every architectural choice above this layer is, in part, a choice about how many tokens — and how much GPU time — it costs.
- The accelerator is also the layer where supply governs price. NVIDIA’s H100/B200 supply, TPU build-out, and the AMD/Intel/AWS challenger trajectory together set the floor on what every layer above pays per useful operation. CPUs went through the same arc — different ISAs, eventually abstracted by compilers and runtimes — but it took twenty years; the AI silicon market is roughly five years into that journey.
Where it strains: process-node scaling has slowed, the high-bandwidth-memory bottleneck is binding, and the cost-per-useful-token curve is bending more from clever architecture in the runtime above (MoE, MLA — the LLM layer’s own scheduling tricks) than from raw silicon improvements. The next twelve months of capability gain comes from how the substrate is used, not from how much faster it gets.
Layer 2 — LLM runtime: the new operating system
If silicon is the new CPU, the LLM is the new operating system — the runtime that turns raw compute below into a usable abstraction above. GPT, Claude, Gemini, Llama, DeepSeek, Mistral and the long tail of open-weight variants are the runtimes the rest of the stack programs against. This is the layer everyone notices first and the layer the trade press writes about most.
The OS-runtime parallel is closer than it looks. An OS interprets a binary into running processes, manages memory, schedules across cores, and exposes a system-call surface that everything above it uses. An LLM interprets a context window into a sequence of decisions, manages its own attention/memory, routes tokens across experts, and exposes a tool-call surface that everything above it uses. The shape is the same; the primitives are different.
Two architectural threads inside the LLM runtime matter for the layers above.
Mixture of Experts (MoE) is the runtime’s per-token scheduling. Modern frontier models route each token to a small subset of specialized “expert” subnetworks. The activated parameter count per token drops by an order of magnitude relative to the total parameter count. Inference is cheaper without losing capability — at least for the workloads where routing finds the right experts. It is the LLM-era equivalent of an OS scheduler deciding which core gets which thread.
Multi-head Latent Attention (MLA) is the runtime’s memory management. The KV cache that used to dominate memory usage drops to a fraction of its prior size, so million-token contexts become physically tractable at acceptable latency. Without it, the “just feed it everything” school of prompting would have stayed an expensive academic curiosity.
Two operational facts shape the rest of the stack from here:
- The LLM is the most expensive runtime, per useful operation, the industry has ever scaled. Every architectural choice above this layer is, in part, a choice about how many tokens it costs.
- The LLM is also the layer where commodity has not yet settled. Switching from Claude to GPT to Llama to Gemini is non-trivial — different context shapes, different tool-use conventions, different latency profiles, different price points. The LLM Gateway in the Action layer above exists precisely to make this layer interchangeable, the same way POSIX made operating systems interchangeable for C programs.
Where it strains: pretraining data is hitting saturation. The next wave of capability gains comes from post-training (instruction tuning, RLHF, RLAIF), tool use during inference, and orchestration over multiple model calls rather than from another order of magnitude of parameters. The LLM runtime is increasingly composed with the layers above it, not separately from them.
Layer 3 — Action: protocols and gateways are the new SDK
If Layer 1 is the silicon and Layer 2 is the LLM that runs on it, Layer 3 is how the model’s outputs reach the world. This is where the agentic economy actually began — the moment someone realized a chat-tuned LLM could call tools, read files, run commands, and act on the results.
Three protocols and two gateways define this layer today.
ReAct (Reasoning + Acting) is the pattern. An agent alternates between a reasoning step (“I should check whether the file exists”) and an action step (calling ls), reads the result, and continues. The pattern is old in symbolic AI; ReAct made it the default inner loop for LLM agents.
MCP (Model Context Protocol) standardized how an agent discovers and invokes tools. Before MCP, every product had its own bespoke tool-use interface — OpenAI function calling, LangChain tools, Claude tool use, dozens of vendor-specific shims. MCP defined a single transport for tool discovery, invocation, and response handling. The effect is the same one HTTP had on networked applications in the 1990s: any client can talk to any server, and the interesting work moves to what the tools actually do.
A2A (Agent-to-Agent) extends the same logic to agent communication. When one agent needs another agent’s capability — a planning agent calling a code-writing agent, a code-writing agent calling a test-running agent — A2A standardizes the discovery, hand-off, and result aggregation. Multi-agent workflows stop being bespoke pipelines and start being protocol-mediated graphs.
LLM Gateway is the operational chokepoint in front of model calls. A gateway sits in front of every model call, providing routing, fallbacks, rate limiting, prompt and response logging, cost attribution, and content filtering. Portkey, Helicone, and Axiom occupy this slot. The LLM Gateway is what turns “we use Claude” or “we use GPT” into “we operate AI” — it makes the LLM-runtime layer something you can audit, optimize, and replace without rewriting your stack.
MCP Gateway is the matching chokepoint in front of tool calls. Where the LLM Gateway brokers model traffic, the MCP Gateway brokers tool traffic — discovering MCP servers, applying tool-level policy, redacting secrets in tool arguments, and rate-limiting tool invocations the same way the LLM Gateway rate-limits model calls. Once an organization runs more than a handful of agents against more than a handful of tools, the MCP Gateway becomes the single place where “what tools is anyone allowed to call, and with what arguments” is answerable.
RAG (Retrieval-Augmented Generation) lives here too. RAG is not an LLM-internal feature; it is a tool call against a retrieval system — the model decides what it needs, the action layer fetches it, the result re-enters the context window. Treating RAG as an Action-layer pattern (rather than a model-architecture pattern) is what lets a single retrieval pipeline serve every model the gateway routes to.
Where it strains: the explosion in protocols has outpaced the maturity of any single one. Every team that adopts agentic coding ends up writing some amount of glue between MCP servers, gateway configurations, agent runtimes, and tool catalogs. The next year of motion at this layer is consolidation, not invention — fewer protocols, deeper interop, better defaults.
Layer 4 — Governance: the layer that decides whether the rest ships
Governance is the layer most people skipped past for the first two years of the agentic economy. It is now the layer that decides whether anything past a pilot ever ships into a regulated enterprise.
The function is simple to state: an AI system has to obey rules, and the rules have to be enforced at runtime rather than written in a slide deck. The rules cover everything from “don’t exfiltrate customer data” to “don’t open a PR without a tracked work item” to “redact secrets from prompts before they reach the model.”
The technologies are deliberately boring, because they have to work every time.
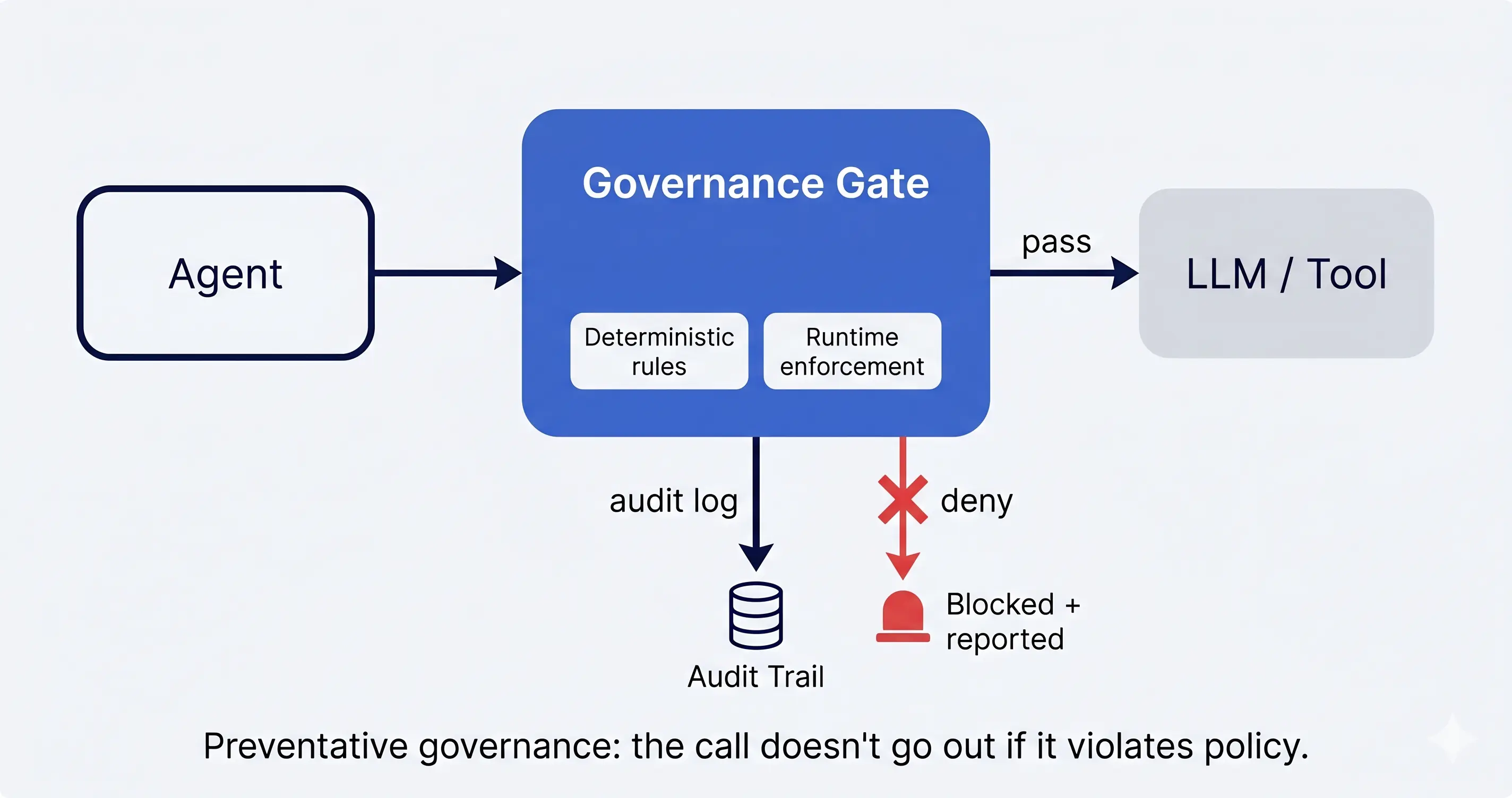
Deterministic rules — allow/deny lists, schema validation, policy expressions evaluated against every request — are the bedrock. Anything probabilistic at the governance layer is a bug. An LLM “deciding” whether to let another LLM exfiltrate data is not governance; it is theater. Deterministic rules are also auditable in a way that LLM-based gates are not: a compliance officer can read the rule, trace its application to a specific request, and produce evidence for an auditor.
Runtime enforcement is where most teams cut corners and pay later. A policy in version control that is not actually evaluated on every model call is documentation, not enforcement. Real governance at this layer is a request-path component: every model call, every tool invocation, every artifact going in or out of the agent’s sandbox passes through it. Bypass it once and the audit trail is broken; an auditor will not accept “we usually enforce this.”
The protocols of Layer 3 actually help here. An MCP-Gateway-mediated tool call has a clean interception point. An LLM-Gateway-mediated model call has a clean interception point. The governance layer’s job is to live at those interception points and apply the deterministic rules consistently.
Where it strains: most “AI governance” products today are dashboards rather than enforcement layers. They surface what happened after the fact. Real governance is preventative — the call does not go out if it violates policy. The market is bifurcating into observability-only tools (useful, but not what compliance officers actually need) and request-path enforcement (rarer, harder to build, the only thing that satisfies SOC 2 and EU AI Act controls). The next twelve months will sort the two camps.
Layer 5 — Orchestration: where the work actually happens
If the lower three layers are how individual model calls work, Orchestration is how multiple model calls become coherent work.
A modern agentic-coding task is not one inference. It is a hundred — read this file, plan, edit, run the test, read the failure, re-plan, edit again, commit, push, open the PR. Each of those steps is a decision point that connects to the steps before and after. The orchestrator is what holds the thread.
Three architectural patterns are converging at this layer.
Tracked work items. Every unit of work is a row in a tracking system — a todo, an issue, a ticket — with a status, an owner (human or agent), an audit trail, and explicit transitions. Agents claim items, work on them, and close them. The work-item state machine is what makes “who is doing what” answerable at any moment.
Durable context. Project-level context (architecture, conventions, decisions), feature-level context (the prior history of work on this surface), and per-task context (what this specific agent run discovered) all live on disk — versioned, structured, read at the start of every task. The agent does not re-discover the codebase every time; it loads what it needs and gets to work.
Worktree isolation. Each agent run gets its own git worktree, its own sandbox, its own scope ceiling. The agent cannot accidentally clobber another agent’s in-flight work. Failures are reversible; bad commits are contained.
These patterns are not optional once a team graduates past one engineer using one agent on one repo. They are the architectural difference between agentic coding as a productivity feature and agentic coding as a discipline.
OpenClaw and the higher-order orchestration stacks built on top of it are the most visible bet that this layer becomes its own product category. They are the operating system for AI agents — work items, context, worktrees, execution logs, review gates — the parts of the agentic economy that do not get written about because they look like infrastructure rather than capability.
Where it strains: most teams discover this layer at exactly the wrong moment, after they have already accumulated a year of untraceable agent commits, half-written context files, and bespoke per-team tooling. The cost of bolting this on retroactively is much higher than building from it. The teams that adopted the orchestration discipline early are now twelve to eighteen months ahead of the ones that did not.
Layer 6 — Economics: the math has to add up
This is the layer that determines whether everything above it survives the end of the subsidy era.
The arithmetic, as it stands in 2026: a single Claude- or GPT-class agent run for a substantive engineering task — read the codebase, plan, edit files, run tests, iterate — costs somewhere between $0.50 and $5 in inference tokens today. On subsidized prices. Some of those subsidies are explicit (free tiers, promotional credits); some are implicit (model providers absorbing GPU cost to capture market share); but the through-line is the same: the unit economics of “agent does the engineering” depend on inference being cheaper to produce than it currently is.
CPU work — checking out a branch, running a linter, applying a deterministic transform, executing a unit test — costs in the microcents to cents range for the same task. The cost gap between a CPU operation and an LLM inference is, depending on the workload, somewhere between three and six orders of magnitude.
When that gap is invisible, the cost of automation feels free. When the gap shows up on a cloud bill — as it now does, for any team that has scaled agentic coding past pilot — the math reverses fast. Automating a $50/hour engineer with a $5-per-task agent looks great. Automating a $50/hour engineer who needs to run 50 tasks per day with a $5-per-task agent does not look so great anymore. And those 50 tasks were never really 50 LLM calls; they were 50 LLM calls plus thousands of CPU operations that the LLM was kicking off, watching, and re-running.
The current economic structure asks the LLM to do the thinking and the bookkeeping. The bookkeeping is where the math breaks.
Per-task business models are the question, not the answer
The economics layer is the youngest of the five. Per-token pricing, per-seat pricing, per-task pricing, outcomes-based pricing — every model is being tried, and none of them are settled. The pattern that looks durable, to us, is one where the cost of a task is composed of:
- A small, explicit GPU cost for the reasoning steps that genuinely needed reasoning.
- A near-zero CPU cost for the bookkeeping steps that just need execution.
- A clear attribution back to the work item that produced the cost.
Without that decomposition, “AI is expensive” stays a vague complaint. With it, the cost question becomes tractable — every team can see which tasks are worth the GPU budget and which were burning tokens on glorified scripting.
Sensible AI: the synthesis across Orchestration and Economics
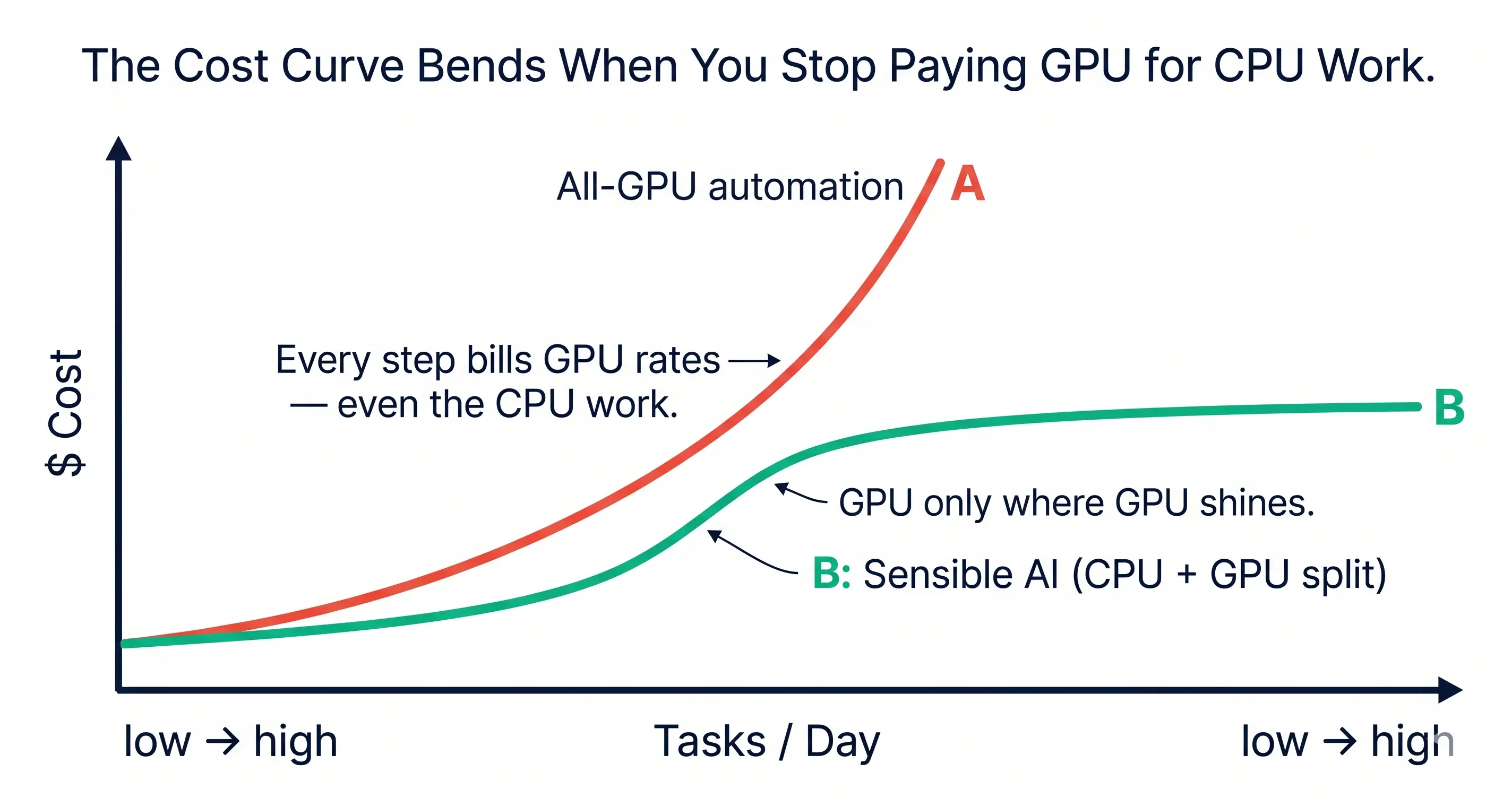
There is a way out of the tokenomics squeeze, and it lives at the intersection of Layers 4 and 5. We call it sensible AI: an architecture that splits work along the line where work naturally splits.
- GPU does what only GPUs can do well: reasoning about ambiguity, writing novel code, deciding what to do next when the right answer is not obvious, synthesizing context from heterogeneous inputs, judging whether a diff is actually correct.
- CPU does what CPUs have always done well: deterministic transforms, branch ops, test runs, indexing, log scanning, the entire grunt of mechanical bookkeeping that today gets billed at GPU token rates because it happens to sit inside an LLM loop.
- Humans do what humans have always been irreplaceable at: judgment under genuine novelty, the call on whether a particular approach is the right approach, the moments where intent and constraint matter more than execution.
The cost curve of sensible AI is fundamentally different from the cost curve of “let the LLM do everything.” It is the difference between paying for thinking and paying for typing. Once you architect for the difference, the agentic economy becomes one where automation costs less than the work being automated — which is the only sustainable shape it can take.
A worked example: a document-processing agent
To make the split concrete, here is a typical document-processing agent — the kind a regulated-industry team would build to extract structured data from inbound PDFs. Eight of the ten steps are CPU work; two are GPU work. The CPU work is the majority of the elapsed time and all of the routine cost; the GPU work is where the agent actually earns its keep.
The pipeline runs in five stages — Ingest → Extract → Index → Reason → Deliver — ten discrete processing steps between the user uploading the PDF and the response returning. GPU steps are bold in the Tier column; the other eight are CPU.
| # | Stage | Step | Tier |
|---|---|---|---|
| 1 | Ingest | Orchestrator (route and claim) | CPU |
| 2 | Ingest | Work-item state machine | CPU |
| 3 | Extract | OCR and text extraction | CPU |
| 4 | Extract | Chunk and index | CPU |
| 5 | Index | Embedding model | GPU |
| 6 | Index | Vector store | CPU |
| 7 | Reason | Reasoning model | GPU |
| 8 | Reason | External API integration (tool call) | CPU |
| 9 | Deliver | Format output | CPU |
| 10 | Deliver | Audit log | CPU |
The orchestrator routes the task. OCR, chunking, the vector store, the API integration, the output formatter, and the audit log are all deterministic — they run on CPU at microcents per task. The embedding model and the reasoning model are GPU, because that is where genuine inference earns its keep.
In the all-GPU shape — where a single agent driven by the LLM does every step inside its own loop — those eight CPU steps run as LLM tool calls instead of as direct CPU operations. Each one bills at GPU rates. Each one also adds tokens to the context window, compounding the cost. The all-GPU shape can do the work; it just cannot do it at a price that survives scale.
VibeFlow: a sensible-AI worked example
VibeFlow is our bet on what this split looks like in practice for the AI software-development lifecycle. It is an Orchestration-layer product with Governance-layer guarantees built in.
In a typical agentic-coding setup today, the LLM is the entire control plane. It plans the task, picks the files, edits them, runs the tests, reads the output, decides what to do next, writes the commit message, opens the PR. Every one of those steps costs GPU tokens, regardless of whether the step required GPU-class reasoning.
In VibeFlow, the control plane is split. The work-item state machine — claim, plan, implement, review, ship — runs on CPU. The context system — durable per-project and per-feature memory, the audit trail, the heartbeat-based stall detector — runs on CPU. The worktree isolation, the git plumbing, the execution-log structure, the eval routing, the cost attribution — all CPU. The LLM is invoked only at the moments where reasoning is the rate-limiting step.
The governance layer is wired into the same control plane. Every model call goes through the gateway. Every tool call is logged. Every commit is linked to a tracked work item. Every artifact is attributable to a specific persona, a specific model version, and a specific input context. SOC 2 controls are not bolted on; they are how the system is built.
The result is a stack where you can run an agentic-coding team at materially lower token cost than the all-GPU equivalent, with stronger governance because the audit trail is not a model summary — it is what actually happened. Sensible AI is not “less AI”; it is AI where the expensive part is doing the expensive work.
Solving the context and memory problem
The agentic economy’s second underwater bill — after the CPU/GPU mismatch — is context. Every long-running agent task starts by re-loading what the agent needs to know: codebase structure, conventions, prior decisions, the architectural why behind each design choice. Today most teams pay this cost in tokens, every task, every run. The model rebuilds its understanding of the codebase before it does anything useful.
The fix is not bigger context windows — bigger windows make the bill worse, because more of every call is now spent rehearsing what the agent already knew an hour ago. The fix is durable, structured, versioned context that lives on disk (or in a database), that the agent reads selectively, and that survives between sessions. This is the LLM runtime (MLA-enabled long context) and the Action layer (RAG against the durable context store) and the Orchestration layer (per-project / per-feature context files) working together.
Context, properly engineered, is the first-class artifact that turns an agent from a stateless tool into an institutional collaborator. It is also the artifact that does the most to bend the cost curve, because every token that an agent spends not re-discovering what is already known is a token spent on actually moving the work forward.
The same logic extends to memory. An agent that learns something on Monday — that this codebase prefers explicit error returns, that the deployment pipeline rejects PRs without test coverage, that a particular vendor’s API throttles at 60 rpm — should not have to re-learn it on Tuesday. Today, most agents do. Sensible AI does not.
Persona-based AI: the 50–60× human
The third place sensible AI bends the curve is in how it organizes the work itself.
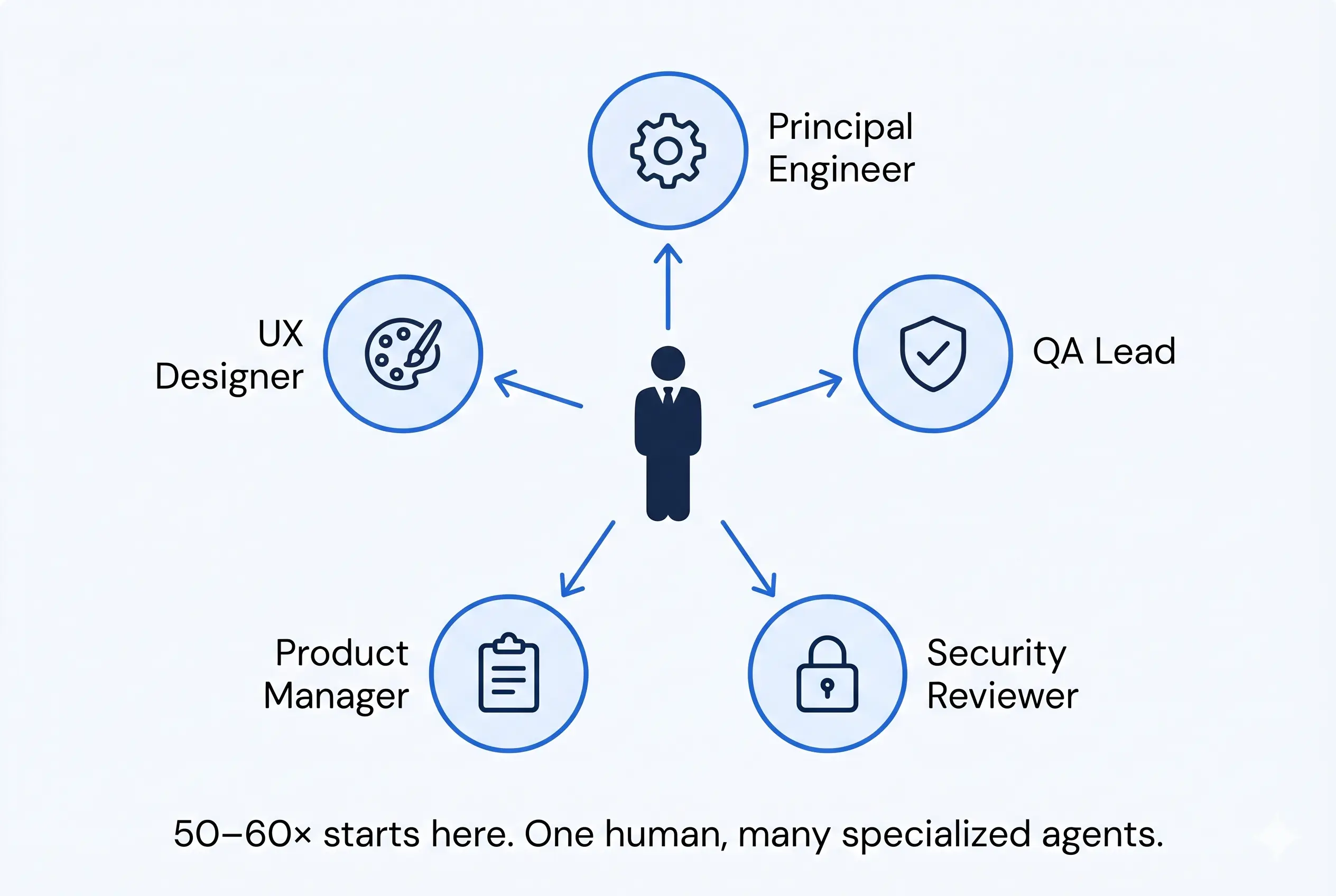
A single general-purpose agent that “can do anything” is the maximally expensive shape — it has to load all context for all tasks, it has to be smart enough to handle the hardest case, and it cannot specialize. A set of personas — a Principal Engineer, a QA Lead, a Security Reviewer, a Product Manager, a UX Designer — each with its own context, its own scope, its own evaluation criteria, is the cheaper and better shape. Each persona is loaded with only the context it needs. Each persona is good at one thing. The orchestration layer routes work to the persona that should do it.
This is what makes a 50–60× more productive human possible. Not because the human is doing the work of fifty people, but because the human is now the conductor of a small orchestra of specialized agents, each one cheap enough to run all day on its narrow scope, each one accountable through the same audit-trailed work-item flow. The human’s job becomes the part of the work that only humans can do — judgment on direction, judgment on tradeoffs, judgment on which problems are worth solving in the first place.
The 50–60× multiplier does not come from replacing the engineer with an agent. It comes from giving the engineer a team of agents who actually take direction.
How we get from here to there
The path from where we are to sensible AI is mostly a path of restraint and discipline rather than novelty. Five moves, indexed to the layers.
- (Economics) Stop paying GPU rates for CPU work. Audit your agent workflows. Anything an agent is doing that a deterministic script could do — file globbing, log scanning, test execution, git plumbing — should run on CPU. The token bill drops accordingly.
- (Intelligence + Orchestration) Make context a durable artifact. Project context, feature context, prior-decision context — written to disk, versioned, read by every agent run. Stop letting every task re-discover the codebase.
- (Orchestration) Specialize your agents. One general-purpose agent for everything is the expensive shape. A small library of persona-tuned agents, each with its own scope and context, is the sustainable one.
- (Governance) Govern the loop at runtime, not after the fact. Worktree isolation, tracked work items, human review gates, audit-trailed execution logs, request-path policy enforcement. These are not overhead; they are how you keep accountability when the agent is doing the typing.
- (Humans) Keep humans where humans matter. Direction-setting, novel-problem judgment, the architectural decisions whose downstream consequences span years — these stay with the humans. Free them from the parts of the job that an agent (or a CPU) can do faster and cheaper.
The agentic economy as it stands today is impressive and unsustainable in equal measure. The six-layer stack — Silicon, LLM runtime, Action, Governance, Orchestration, Economics — is the framework for understanding why, and the parallel to the pre-AI CPU/OS/K8s stack is the reminder that this is not the first time the industry has solved these problems. The path to sensible AI is the route from impressive-and-unsustainable to impressive-and-durable. The LLM runtime and the Action layer are getting cheaper. Orchestration and Governance are getting more rigorous. Economics is the layer where the subsidies will end first; the architectures that prepared for that ending are the ones that will still be running afterward.
VibeFlow is one bet on that shape. The bigger bet is that the industry, collectively, learns to stop billing typing at the rate of thinking. Whichever stack you build on, that is the move.
Written by
AXIOM Team