





Scaling AI is hard
Teams building with AI face compounding complexity as they grow. Every new provider, model, and environment multiplies the operational burden — and the governance gaps.
Vendor Lock-In
Switching from OpenAI to Anthropic means rewriting every integration point across your codebase.
No Governance
There's no single place to set policies, enforce guardrails, or audit who called which model — and what it cost.
Credential Sprawl
Each developer, each environment, each service has its own API keys with no central management.
Silent Failures
When a provider goes down at 2 AM, your users find out before your team does.
Cost Surprises
The invoice arrives at the end of the month with no breakdown by model, team, or use case — and no quotas to prevent it.
Multi-Cluster Sprawl
Managing AI infrastructure across staging, production, and regional clusters means duplicated config and no unified view.
The difference LLM Gateway makes
Go from scattered, unmanaged AI integrations to a unified, observable, and policy-driven infrastructure.
Before Axiomstudio
Drop-in replacement
No code changes. Point your code at one endpoint — the gateway handles the rest.
Your application sends requests to the gateway endpoint
The gateway routes to the right provider with load balancing and failover
Analytics, audit logs, and metrics are captured automatically
18+ providers supported
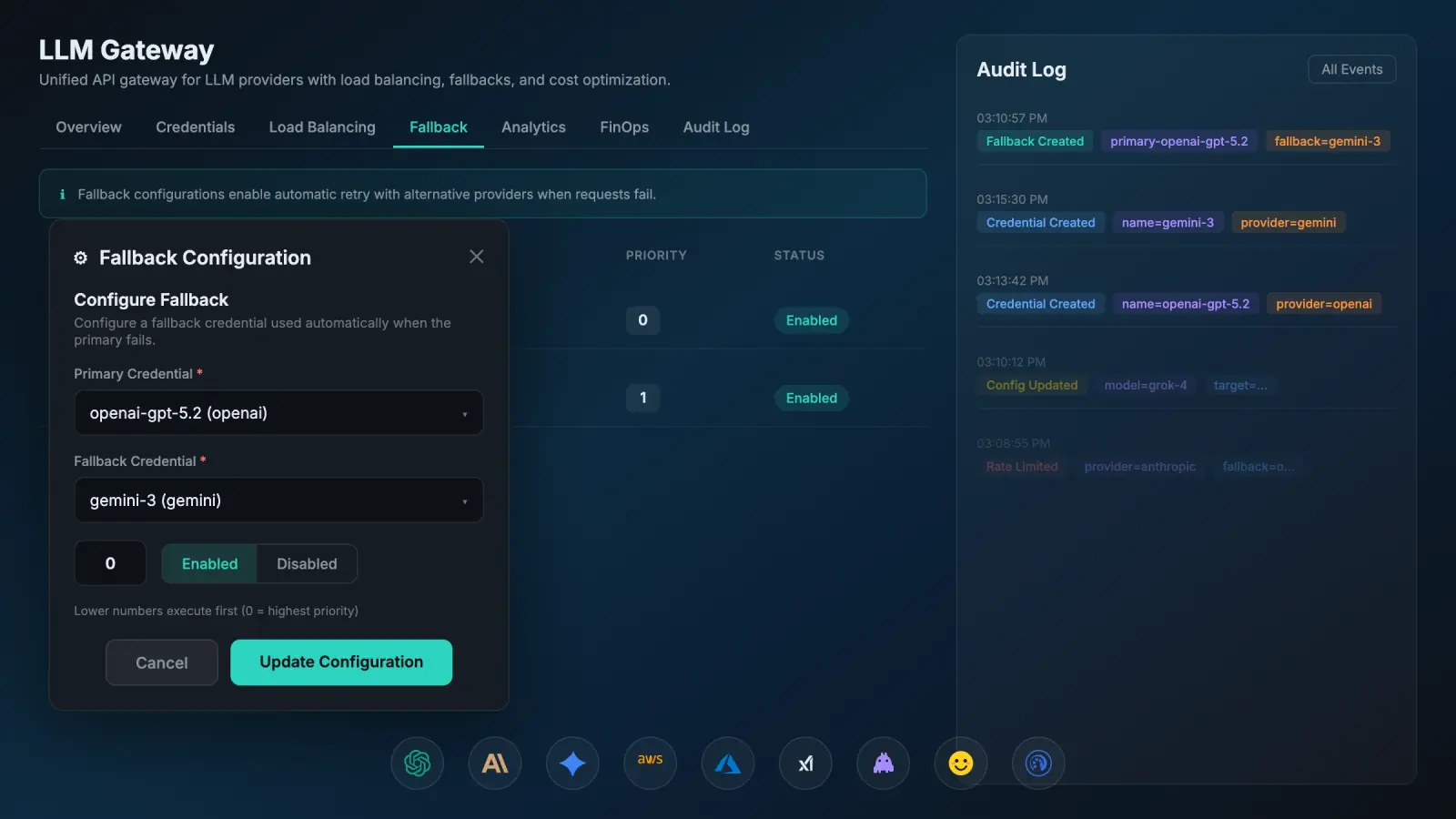
Everything you need to govern AI at scale
Six integrated capabilities that give you enterprise-grade control, governance, and guardrails over your AI infrastructure.
Unified API Across 18+ Providers
Route requests through a single OpenAI-compatible endpoint. The gateway infers the target provider from the model name or your credential configuration.
- Chat completions, embeddings, images, and audio/speech
- Streaming (SSE) supported for all chat providers
- No SDK changes required — use standard OpenAI client
- Provider auto-detection from model name
from openai import OpenAI
client = OpenAI(
base_url="https://your-axiom-cloud-host/rest/v1/llm-gateway/v1/",
api_key="your-api-key"
)
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello!"}]
)See every token, every dollar
Tokenomics and cost measurement are built in. The gateway meters every request — prompt, cache write, cache read, and completion tokens — and prices it per provider and model, so spend is a live dashboard, not a month-end surprise.
Usage by provider
Per-provider spend with a full token-type breakdown — the view your finance and platform teams can share.
| Provider | Requests | Tokens (prompt · cache write · cache read · completion) | Avg latency | Cost |
|---|---|---|---|---|
| anthropic | 4.2K | 2.5M410.7K · 10.4M · 1,247.0M · 2.1M | 8.97s | $743.25 |
| openai | 998 | 119.5M119.3M · 0 · 115.8M · 140.6K | 6.08s | $119.49 |
Illustrative gateway analytics. Cache reads are billed at a fraction of input rates, so the per-token-type breakdown is what reveals where spend actually goes.
Kubernetes-native from the ground up
Integrates seamlessly with your Kubernetes infrastructure, supports HPA, Prometheus ready metrics, and HELM chart.
Kubernetes Native GitOps
Manage your gateway fleet with available ArgoCD CI/CD pipeline option.
Flexible Storage
SQLite for development and edge deployments. PostgreSQL + Redis for production scale with horizontal pod scaling.
Cache-First Inference
Warm cache serves requests with zero database queries. Cache invalidation propagates via Redis pub/sub within seconds.
Prometheus Metrics
Native Prometheus endpoint for direct integration with your existing Grafana stack. Bearer token authentication included.
Embedded Management UI
The management interface is compiled into the binary. No separate frontend deployment, CDN, or static asset hosting.
Multi-Tenant Isolation
All data scoped to organization and user. No cross-tenant data leakage at the database, cache, or metrics layer.
Built for enterprise scale
Enterprise-grade guardrails for organizations that need governance policies, quotas, rate limiting, and traffic shaping.
SSO & Enterprise-Grade Control
SAML 2.0 and OIDC support for enterprise identity providers. Role-based access control with policy-driven, organization-scoped permissions and governance audit trails.
Semantic Caching
Cache responses for semantically similar requests. Reduces cost and latency for repeated or near-duplicate queries with configurable TTL and policy-aware cache rules.
Rate Limiting, Quotas & Traffic Shaping
Enforce guardrails with requests per minute (RPM) and tokens per minute (TPM) quotas. Per-user rate limiting and traffic shaping across your organization.
FinOps & Governance Dashboard
Actual vs. estimated cost comparison, breakdown by provider and model, spend quotas with automated alerts, and governance reporting by team and credential.