AI Tokenomics: Comparing Token Costs Across Claude, OpenAI, Gemini, and Cursor
Tokenomics explained: input, output, cache-read and cache-write tokens, a Claude vs OpenAI vs Gemini vs Cursor cost comparison, and how to measure it.
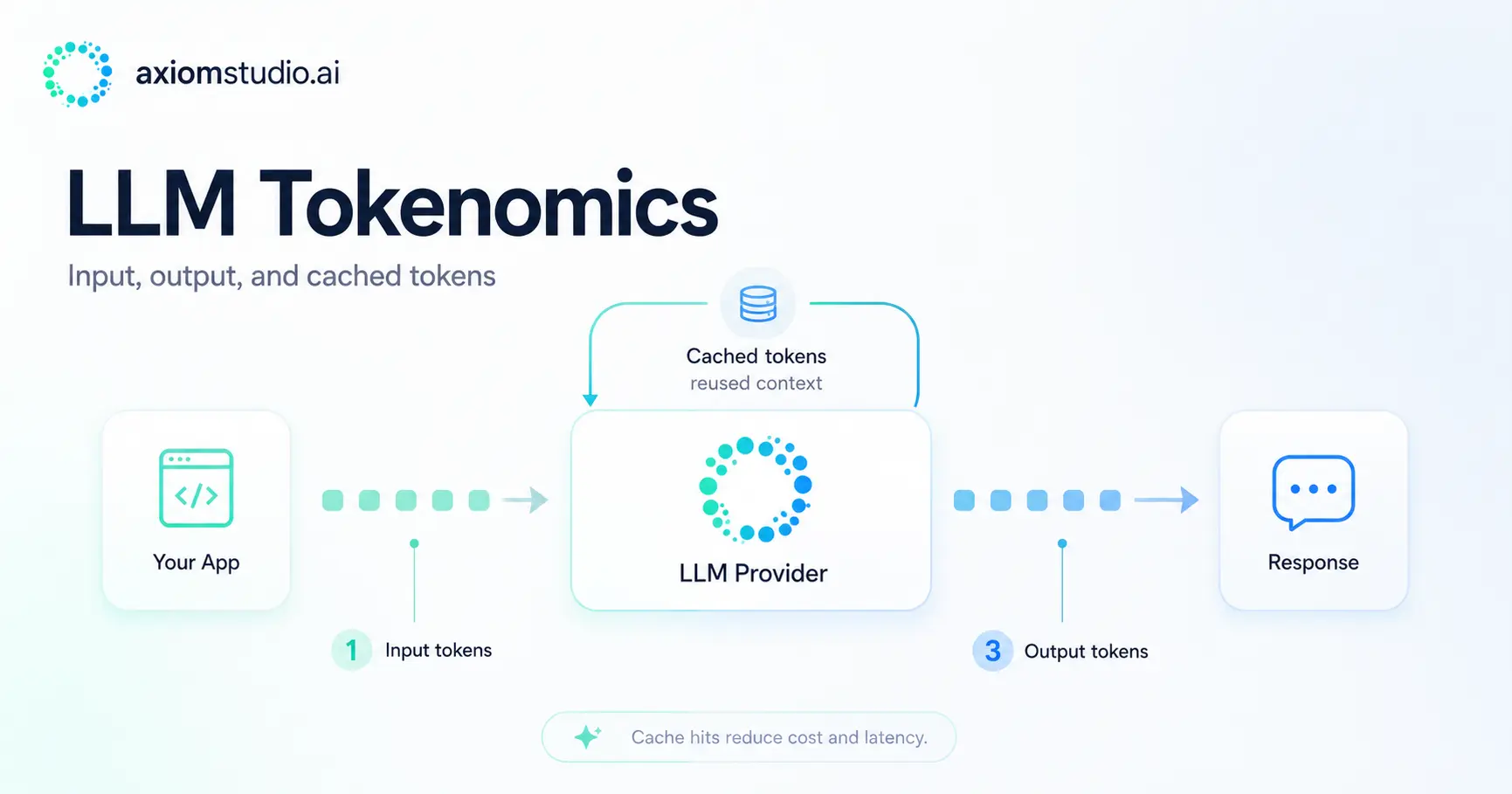
Every LLM bill comes down to a single unit: the token. But tokenomics — the economics of how tokens are consumed and priced — is more complicated than one per-token rate. Two teams running the same model can see wildly different bills depending on how much of their traffic is input versus output, how much context is cached, and whether they are reading from or writing to that cache.
This post breaks down the anatomy of token consumption, compares list pricing across Claude, OpenAI, Gemini, and Cursor, shows how to pull token and cost data from each provider’s API, and explains how an LLM gateway turns all of it into a single cost view.
The Anatomy of Token Consumption
Four token types drive almost every bill:
- Input (prompt) tokens — everything you send: the system prompt, conversation history, retrieved context, and the user’s message.
- Output (completion) tokens — what the model generates. These are the most expensive per token, typically 5x to 8x the input rate. On reasoning models, “output” also includes hidden thinking tokens.
- Cache-write tokens — when you store a block of context for reuse, the act of writing it into the cache. Some providers charge a premium for the write.
- Cache-read tokens — when a later request reuses that cached context. These are heavily discounted, often around 90% off the input rate.
The read/write distinction is where most teams misjudge cost. Caching a large system prompt or codebase once (a write) and reusing it across thousands of requests (cheap reads) can cut spend dramatically — but only if your request pattern actually reuses the cache before it expires.
Why Costs Differ Across Providers
Three structural facts shape every comparison:
- Output costs far more than input — usually 5x to 8x. A chatty agent that generates long answers costs far more than one that reads a lot of context and replies tersely.
- Cache reads are cheap; cache writes may not be. Anthropic charges a write premium (1.25x input for a 5-minute cache, 2x for one hour) and bills cache reads at 0.1x input. OpenAI caches automatically with no separate write charge and bills cached input at roughly 10% of the input rate. Gemini’s context caching discounts reads to about 10% of input but adds an hourly storage fee.
- Long context can cost more. Gemini 2.5 Pro doubles its input price above 200K tokens; OpenAI’s GPT-5.5 charges 2x input and 1.5x output above roughly 272K tokens for the rest of the session.
Pricing comparison (flagship models, list rates, per 1M tokens)
List prices as of mid-2026 — always confirm on each vendor’s pricing page, because these rates change frequently:
| Provider / model | Input | Cached input (read) | Output |
|---|---|---|---|
| Anthropic Claude Opus 4.8 | $5.00 | $0.50 | $25.00 |
| OpenAI GPT-5.5 | $5.00 | $0.50 | $30.00 |
| Google Gemini 2.5 Pro (≤200K) | $1.25 | ~$0.13 | $10.00 |
| Cursor | subscription + usage-based (see below) | — | — |
Sources: Anthropic pricing, OpenAI pricing, Gemini pricing, Cursor pricing. Claude additionally charges a cache-write premium (about $6.25/1M for a 5-minute write, $10/1M for a one-hour write); Gemini context caching adds an hourly storage fee; batch or async modes cut roughly 50% off most providers.
Cursor is a different animal
Cursor is a coding tool, not a token API, so its cost works differently. Since mid-2025 it bills on usage credits: each plan — Pro at $20/month, Pro+ at $60/month, Ultra at $200/month, Teams from $40/seat — includes a dollar-denominated credit pool. Auto mode routes to a cheap blended model (around $1.25/1M input, $6/1M output, $0.25/1M cache read) and does not draw from credits. Manually selecting a premium frontier model (Claude, GPT, or Gemini) or running Max mode draws from the pool at the underlying provider’s per-token rates, and overages bill in arrears. So a Cursor seat’s effective token cost is the same provider rates above, wrapped in a subscription with an included allowance.
How to Read Token and Cost Data From Each API
You cannot manage what you cannot measure, and every provider returns token counts on each response:
- Anthropic — the
usageobject:input_tokens,output_tokens,cache_creation_input_tokens(writes), andcache_read_input_tokens(reads). - OpenAI —
usage:prompt_tokens,completion_tokens, andprompt_tokens_details.cached_tokensfor the cached portion of the prompt. - Google Gemini —
usageMetadata:promptTokenCount,candidatesTokenCount,cachedContentTokenCount, andtotalTokenCount. - Cursor — per-call token usage is not exposed the way the model providers expose it; team admins read spend and usage from the dashboard and the admin usage API on Team and Enterprise plans.
Multiply each token category by its matching rate and you have the cost of a request. Do it across providers, models, and time and you have tokenomics. The catch: every provider names the fields differently and prices them differently, so a multi-provider deployment needs one place that normalizes all of it.
Measuring Tokenomics With an LLM Gateway
That normalization layer is exactly what an LLM gateway provides. Because every model call flows through it, the gateway captures the token breakdown and applies each provider’s rate card to produce a single, comparable cost view.
Here is how the LLM Gateway presents per-provider usage — the same data the provider APIs return, normalized and priced:
| Provider | Requests | Tokens (prompt / cache-write / cache-read / completion) | Avg latency | Cost |
|---|---|---|---|---|
| anthropic | 4.2K | 2.5M — prompt 410.7K / cache-write 10.4M / cache-read 1,247.0M / completion 2.1M | 8.97s | $743.25 |
| openai | 998 | 119.5M — prompt 119.3M / cache-write 0 / cache-read 115.8M / completion 140.6K | 6.08s | $119.49 |
The breakdown is where the insight lives. Take the Anthropic row: at Opus 4.8 list rates, the 1,247M cache-read tokens cost about $624 (1,247 × $0.50), the 10.4M cache writes about $65, the 2.1M completion tokens about $53, and the prompt tokens about $2 — which adds up to roughly the $743 the gateway reports. Even at $0.50 per million, cache reads dominate the bill at that volume. Without the per-type split, you would assume output length drove the cost; in fact, caching strategy did.
The gateway also rolls these figures into live operational metrics — request rate, tokens per minute, latency percentiles, error rate, and a real-time cost rate. In the window above, that was $202.11 per hour against a 24-hour total of $862.74. That turns tokenomics from a month-end surprise into a dashboard you can watch.
From Token Counts to FinOps
Tokenomics is the foundation of AI FinOps. Once you can attribute spend to a specific team, feature, model, and token type, you can catch a runaway agent before the invoice arrives, pick the cheapest model that still meets your quality bar, and show finance exactly where the money goes. A gateway gives you the per-token, per-provider, per-model truth that siloed vendor dashboards — each with its own field names and its own billing window — cannot.
Pair that cost visibility with governance through VibeFlow, and every agent action carries both an audit trail and a price tag. Cost and control stop being separate problems.
Final Thoughts
The per-token rate on a pricing page is the smallest part of your real bill. Input versus output, cached versus fresh, read versus write, and short versus long context each move the number more than the headline rate does. Compare providers on the full tokenomics — not the input price alone — and measure actual consumption through a single gateway so the comparison is grounded in your traffic, not a vendor’s example.
Written by
AXIOM Team